
Why Vertical SaaS is Riding the Waves of AI to New Heights

Recent interviews from Andrej Karpathy, research papers on ArXiv, and analogies to the human brain point to near term model advancements that will be a huge boon for vertical applications.
While there is certainly some interest in Vertical SaaS in public or private markets: Harvey & EvenUp (legal vertical), Abridge & OpenEvidence (medical vertical), Owner (restaurant vertical), there’s far more attention being paid to horizontal SaaS like Runway, Glean, HeyGen, ElevenLabs, Cursor, Clay, Sierra, etc. On the one hand, in a new market horizontal applications have a much bigger TAM so the valuations that could potentially be achieved are much higher. On the other hand, vertical SaaS can scale just as rapidly with more defensibility from the vertical specific workflows, relationships, and data moats. Notice Perplexity is going deeper and deeper into the finance vertical and Snowflake just announced Cortex AI for financial services. As companies scale, they start to lean into certain verticals as packaged solutions can lead to more efficient GTM motions. For more on this topic, feel free to read my prior post from 2022 on the Verticalization of Software. With recent advancements in AI, I believe we are about to see an explosion in vertical SaaS products scaling more efficiently and just as fast as their horizontal counterparts.
Andrej Karpathy LLM Worldview
Before we go further, the most important podcast of 2025 for understanding the progress of LLMs is this podcast between Dwarkesh and Andrej Karpathy. Please give it a listen if you haven’t yet.
A point that stood out to me in this podcast was the discussion around the Cognitive Core. This important concept is what Karpathy describes as the fewest amount of parameters needed for the model to have a base level of knowledge about most things. Instead of trillion parameter models, Karpathy argues that a 1B parameter model may be optimal. The reason for this is simple, if we use the human brain as an analogy. Imagine a student is trying to study for a driver’s test. At the same time, the student has their school finals. In most cases, the student is trying to ingest, learn, and memorize the knowledge needed to past these tests. Inevitably, with all that context loaded in, the brain begins thinking about right of way at a stop sign while trying to figure out the cosine function of an angle.
In Karpathy’s optimal world, a smaller 1B parameter model would have just enough context stored in memory and then would utilize tool calling, RAG, consulting with experts, fine-tuning, and reasoning to arrive at the optimal answer or result. This is much more akin to how we work as humans. We don’t typically have all the context for a certain task, but we REASON through it calling on help, reading articles, and making informed decisions to reach a conclusion. Karpathy used to lead Tesla’s autopilot team and co-founded OpenAI, however we don’t just have to take his informed work for it.
Tiny Recursive Networks Paper
Deedy Das put out a great tweet summarizing some of the implications of an important paper. Give him a follow if you want to stay on top of AI research.
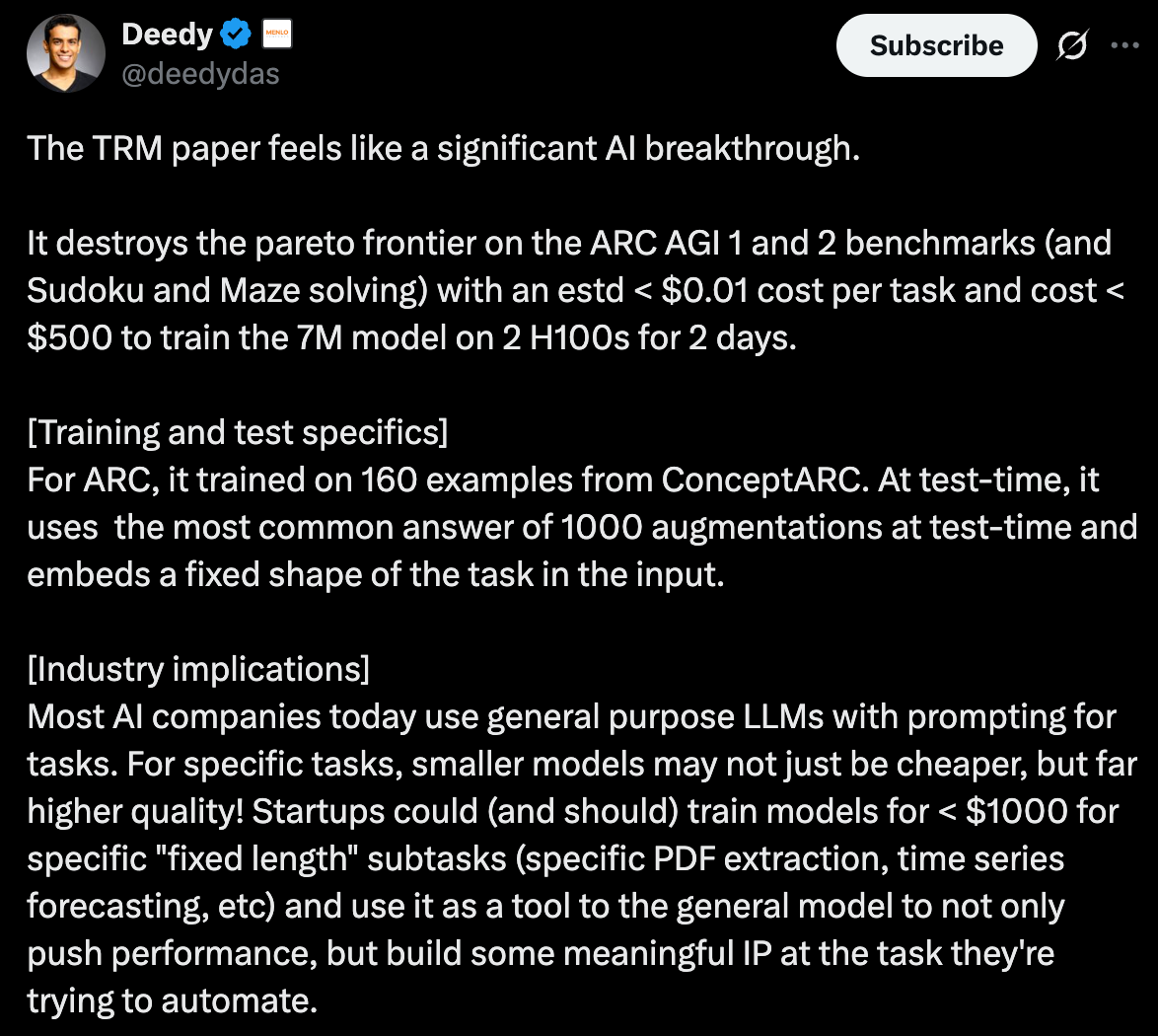
Less is More: Recursive Reasoning with Tiny Networks
Put simply, a 7M parameter model (think <0.01% of the parameters in the large models we generally use and think of) outperformed multi-billion/trillion parameter models in performing specific complex tasks like solving a Sudoku puzzle. It essentially uses repetition and an internal record of the chain of thought (reasoning) of the model to arrive at the best answer. Given it can see it’s own reasoning, it can continue to improve rapidly on its answer at lower training costs and inference costs given the size of the model. The paper’s conclusions match a lot of what Karpathy laid out without the tool calling or expert consultation piece.
Google Pushing the Frontier in Reasoning
recently highlighted an interesting post in his newsletter on a Google research paper called ReasoningBank.Reasoning Bank: Scaling Agent Self-Evolving with Reasoning Memory
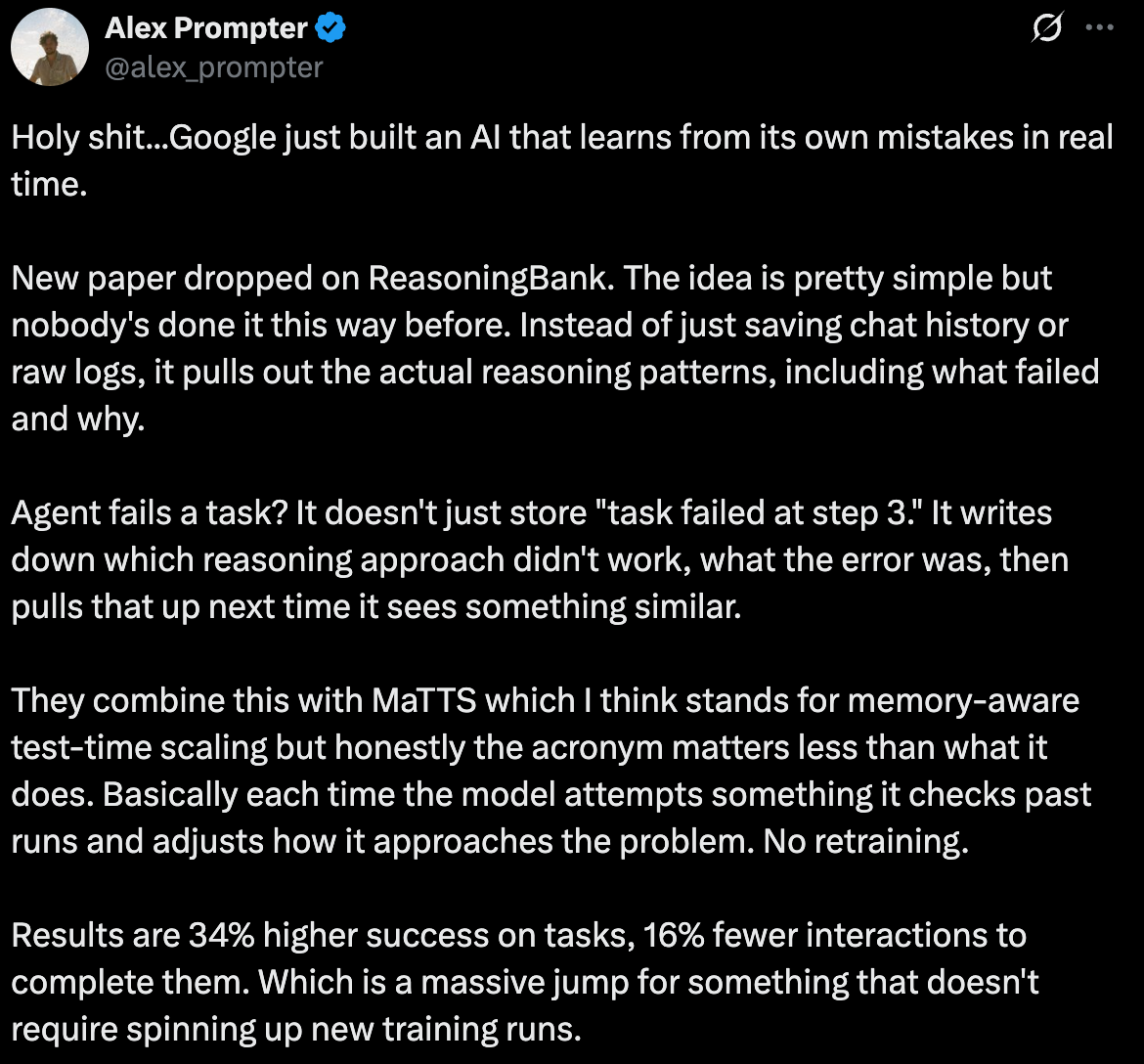
Similar to the Tiny Recursive Networks paper but taking it a step further, ReasoningBank talks about saving the reasoning approach and patterns in a sort of postmortem cookbook that the model/agent can call upon in the future. Google uses Memory Aware Test-Time Scaling to enable the model to look at the cookbooks before performing a task, thereby having recall as to how it thought through the problem previously and being able to improve upon that reasoning or simply reuse it.
This is a huge leap forward as it’s providing a framework for all models to use in order to avoid complex and costly re-training and fine-tuning while optimizing test time compute as the model builds upon it’s reasoning cookbooks on each run.
Implications for Vertical SaaS
Jensen’s point on inference workloads resulting in 100x demand compared to pre-training or training around the Deepseek shock in Feb 2025 seems understated now. With the models being needed for various tasks at smaller parameter counts, more models will be used relying on inference to reason through tasks. This enables more on-device use cases (robotics, physical AI) and implies much more vertical specific payoffs.
Say you are a vertical SaaS company for life sciences like Kneat (readers of my twitter feed will know I’m a huge fan of this company…and for full disclosure an investor too). Kneat collects deep data and knowledge of how the systems, equipment, and processes in a plant work together to produce the product of the customer. This data is currently used by Kneat’s product team to synthesize better workflows for the customer and provide guidance on optimal processes. Now imagine pointing multiple small models at each of these use cases while enabling interaction with a larger model that understands how they all tie together. You can get “ICs” deeply focused on their task and executing optimal pathways while being able to consult with the “CTO” who can help give the global view of how those changes impact the rest of the workflows. This can be served at a decreasing cost to Kneat over time while also saving on human capital needed as the customer base and platform scales. Meanwhile, the customer benefits from having models specialized to their workflows and reasoning on their specific data to uncover insights and efficiencies that would require a team of highly paid consultants years to find out. All of this being stored in a “ReasoningBank” allows for auditability and knowledge dissemination by chatting with the model about how decisions were made and why those were considered to be optimal. Through those chats, the reasoning of the model can improve benefiting future decisions at a faster rate than human to human interaction would enable.
Margins with Vertical SaaS companies are going up as they find operating leverage through using AI products and as they can delight customers more readily with tailored insights & workflows at a fraction of the cost of the models they’re currently using to provide any AI features on the platforms. The data moat of the SaaS company operating in that vertical is more important with the reasoning and tool calling only as good as the data and process knowledge that the model is able to access.
So while horizontal SaaS especially in a new technology wave is always exciting, let’s not forget about vertical SaaS as they have clear tailwinds from model advancements coming their way in the near future.
Regarding the topic of the article, your points on AI boosting vertical SaaS were super insightful and got me really thinkin' about the future landscape. It makes me consider if the unique data moats for these vertical solutions also imply a greater initial effort in finetunig and domain adaptation, potentially slowing down adoption for smaller players at first.